1. 자바 컴파일 과정
개발자가 자바 소스코드를 작성하고,
자바 컴파일러가 자바소스파일을 컴파일한다.
컴파일을 하게 되면, class파일이 생성되어, 아직 JVM만 이해할수 있는 코드가 된다.
컴파일된 바이크 코드를 JVM의 ClassLoader에게 전달을한다.
ClassLoader는 동적 로딩을 통해 필요한 클래스들을 로딩 및 링크하여,JVM 메모리에 올린다.
ClassLoader 세부 동작.
1. 로드 : 클래스 파일을 가져와서 JVM 메모리에 로드한다.
2. 검증 : 자바 언어 명세 및 JVM 명세에 명시된 대로 구성되어있는지 검사
3. 준비 : 클래스가 필요로하는 메모리를 할당한다.
4. 분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경한다.
5. 초기화 : 클래스 변수들을 초기화한다.
실행엔진은 JVM 메모리에 올라온 바이크 코드들을 명령어 단위로 하나씩 가져와서 실행한다.
(쉽게 말해 JVM에 로드된 클래스 파일들을 실행하여, 실제 기계어로 변경한다.)
이때 실행엔진은 두가지 방식으로 변경한다.
1. 인터프리터 : 바이트 코드 명령어를 하나씩 읽어 실행한다. 느리다.
2. JIT 컴파일러 : 인터프리터 방식으로 한줄씩 실행을 하다가, 적절 시점에
바이트 코드 전체를컴파일하고, 해당코드를 직접 실행한다.
JIT 컴파일러는, 한번 컴파일 후에 캐시에 보관하여, 다음 수행 부터는 빠르다.
즉, 한번만 수행될꺼면 인터프리터 방식, 여러번 할꺼면, JIT 컴파일러 방식이
좋다.
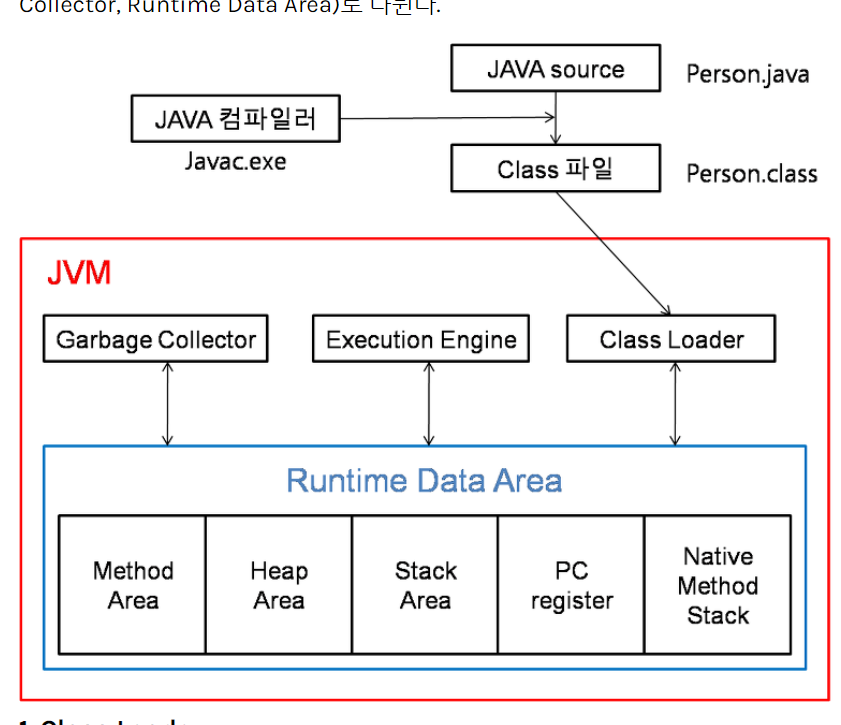
이제 , 컴파일러가 클래스로더, 그리고 실행엔진으로 주고
사용되고 저장되는 JVM 내 메모리 구조에 대해서 알아보자
1. Stack Area
클래스 내의 메소드에서 사용되는 정보들이 저장되는 공간이다.
매개변수, 지역 변수, 리턴값등이 저장되며, LIFO 방식으로 메소드 실행시 저장되었다가.
실행이 완료되면 제거된다.
2. Method Area
클래스,메소드,변수와 상수 정보등이 저장되는 공간
3. Heap Area
New 명령어를 통해 생성한 인스턴스 배열등의 참조형 변수 정보가 저장되는 공간입니다.
물론 Method Area 에 올라온 클래스들만 생성이 가능하다.
GC의 대상이 된다.
4. PC Register Area
쓰레드마다 하나씩 생성, JVM 명령의 주소값이 저장되는 공간이다.
5.Native Method Stack Area
자바 외 다른 언어의 호출을 위해 할당 되는 영역이다.
자바에서 c,c++ 등의 메소드를 호출할때 사용하는 영역이다.
2. 추상 클래스와 인터페이스 차이 및 존재 이유
어떨때 추상, 어떨때 인터페이스를 써야 할까?
우선 추상클래스는 다중상속이불가능하다. 자바의 큰 특징중에하나인, 1클래스 1상속에 대한 개념으로,
다중상속이 불가능하다. 하지만 인터페이스는 다중 구현이 가능하다.
따라서, 자식 클래스에서 클래스의 범위안에서만, 메소드가 필요하다면, 추상화 클래스(상속을 위한 클래스) 로 유지관리하는 것이 좋다.
예를들어서 생명체라는 것에 대한 추상 클래스가 있다고 가정하자
걷고 뛰고 달릴수있다.
만약에 이런 생명체라는 추상클래스를 상속 받으면, 그 상속 받은 클래스는, 걷고 뛰고 달리기중 하나를 구현할수있다.
다른 추상클래스에 있는 기능을 사용하고싶어서, 다중 상속이 불가능하여, 사용이 불가능하다.
하지만, 인터페이스는? 다중 구현이 가능하기 때문에, 여러 인터페이스에서 땡겨올수있다.
예를 들면, 부가기능,특수능력 이라는 두가지 인터페이스가있고, 이를 다중 구현받아서
부가기능의 1번과 특수능력의 1번을 특정 클래스에서 사용한다고하면,
두가지 인터페이스를 impl하고, 기능 구현을 하면된다.
즉, 인터페이스는 추상클래스의 1클래스 1상속에 대한 부분을 탈피하기 위해 만들어진 것이다.
또한 추상 클래스는, 추상메소드,일반 메소드 둘다 가질수있지만 인터페이스는 추상 메소드만 가질수있다.
그러면, 원론적으로 인터페이스를 왜 만들까?
사실 메소드이름만 정의해놓고 굳이 매번 서비스 impl을해야할까...? 그냥 각각 다 따로 만들면 되지않나...?
장점은 여러가지가 있다.
1. 개발자가 여러명일때, 인터페이스에 대한 메소드 규약만 해놓고, 한명이 기다리지 않고 바로개발을 할수있다.
개발자 A가 사람클래스의 말하다 기능이 필요해서 메소드를 구현하려고한다. 이를 가지고 공통으로 인터페이스를 만들려고하는데, 개발자 B는 동물의 말하다 기능이 필요하다. 그러면 개발자A의 작업이 끝나고, 이 작업을 가져다가 쓰고, 동물에 맞춰서 수정한뒤에, A,B작업에 대한 테스트를 하면 될까? 그러면 개발자 B가 작업하다가 A에 대한 영향을 주면 ?
문제가 많다.
2. 코드 중복이 줄어, 유지보수에 용이하다.
3. 정형화된 개발을 개발자에게 강요할수 있다.
사실 인터페이스의 사용용도는 개발이 아닌 설계의 패턴이다.
복잡하고 큰프로젝트를 느슨한 결합으로 인해, 단순하게 표현하는 방식으로 생각하면된다.
예를 들어서, 각기 조금씩 다른 내용이 필요한 메소드를 짠다고 치자
a key를 넣으면 a b key를 넣으면 b 이런식으로말이다.
이때, 인터페이스를 구현하지 않는다면...?각각의 처리 클래스를 만들어야 하고,
이를 공통화 하기위해서도, 소스가 서로 다른 케이스를 위해서 굉장히 난잡해질 것이다.
하지만 인터페이스를 사용하여, 추상메소드, 변수로만 제어를 한다면 굉장히 소스가 간결해진다.
또한 controller에서 인터페이스가 구현된 애를 쓰다가 도저히 안되겠으면, 동일 인터페이스를 구현했지만,
소스가 다른 다른 구현체를 사용하면 해결 되기 떄문이다,.
3. ArrayList과 LinkedList 의 차이
ArrayList 는 한덩어리의 큰 배열을 사용하는 방식이다.
반명, LinkedList는 양방향 연결 리스트로 구현이 되어있다.
각각의 데이터는 노드로 구성되어, 서로 연결이 되어있고, 각각 다음노드, 이전노드에 대한값을 내부적으로
가지고있다.
주로 큐의 형태를 가진다고 보면된다.
따라서 ArrayList는 검색이 많은 경우
LinkedList는 삽입,삭제가 많은 경우에 사용한다.
'[Computer Science]' 카테고리의 다른 글
| 잡다하지만 필요한 기술지식 6 (0) | 2021.07.23 |
|---|---|
| 잡다하지만 필요한 기술지식 5 (0) | 2021.07.22 |
| 잡다하지만 필요한 기술지식 3 (0) | 2021.07.19 |
| 잡다한 기술지식 2 (0) | 2021.07.14 |
| 잡다한 기술 지식_1 (0) | 2021.07.14 |
