1. MultiThread

멀티 쓰레드 스탭은, 싱글 쓰레드 스탭보다 조금 더 빠르게 Chunk 단위로 작업을 처리할 가능성이 있다.
멀티 쓰레드 스탭은 TaskExecutorRepeatTemplate을 사용해 처리된다.
Job에 해당 하는 Step -> 해당 템플릿을 통해서, Chunk단위로 작업이 처리된다.
1. Job이 처리되고 Step이 처리된다.
2. Step은 TaskExecutorRepeatTemplate을 생성하고, 각 쓰레드 수만큼 Runnable 객체를 만들어 실행한다.
3. 생성된 Runnable은 RepeatCallback을 호출한다.
4.RepeatCallBack함수는 ChunkOrientedTasklet을 수행하고, 독립적으로 ItemReader,ItemProcessor,ItemWriter를 이용한다.
DB 동시성 문제가 발생할 수 있기때문에, ItemReader 부분은 무조건 동기화 처리를 해야한다.

내부적으로 TaskExecutorRepeatTemplate은, 쓰레드 4개와 SYncTaskExecutor를 지원한다.
또한 쓰레드 기본 제한 은 4개로 지정한다.

TaskExecutorRepeatTemplate내 쓰레드는 내부적으로 아래의 함수를 호출하여 실행한다.
해당 실행함수에는 콜백함수,context, que인데, que에는 RepeatStatus를 가지고 있다.(반복/실행중/종료)

1. TaskExecutor는 지정된 수만 큼 쓰레드를 생성한다. 그리고 그 쓰레드는 내부적으로 Runnable을 실행한다.
2. Runnable은 ChunkOrientedTasklet이다. ChunkOrientedTasklet은 내부적으로 쓰레드 별로 Chunk를 만들어서
Reader,Processor,Writer를 실행한다. 따라서 해당 작업은 Thread free하다.
SimpleChunkProvider는 input chunk를 제공한다.
Input Chunk는 매번 새롭게 만들어서 전달 되기 때문에 Thread free하다.
생성된 InputChunk는 각자 다른 주소를 쓰고있기 때문에 동기화 기능이 제공되는 ItemReader만 사용하면, 멀티쓰레딩 환경에서 편하게 사용가능하다.
사용하는 방법은, taskExecutor에 구현된 걸 사용하기만하면되고
reader는, PagingItemReader()나 동기화가 보장되는 reader를 사용하면된다.


해당 과 같이 Job을 생성해준다.
해당 Job은 MultiThreadJob으로 잡고, multiThreadedStep을 실행시킨다.

해당 Step은 multiThreadStep이다.
해당 step에서 reader,writer,processor, 그리고 멀티쓰레드 처리를 위한 taskExecutor를 설정해준다.

우선 멀티쓰레드 처리를 위한 TaskExecutor이다.
해당 최대 풀싸이즈와 코머 풀사이즈를 지정해주고, 리턴해준다.
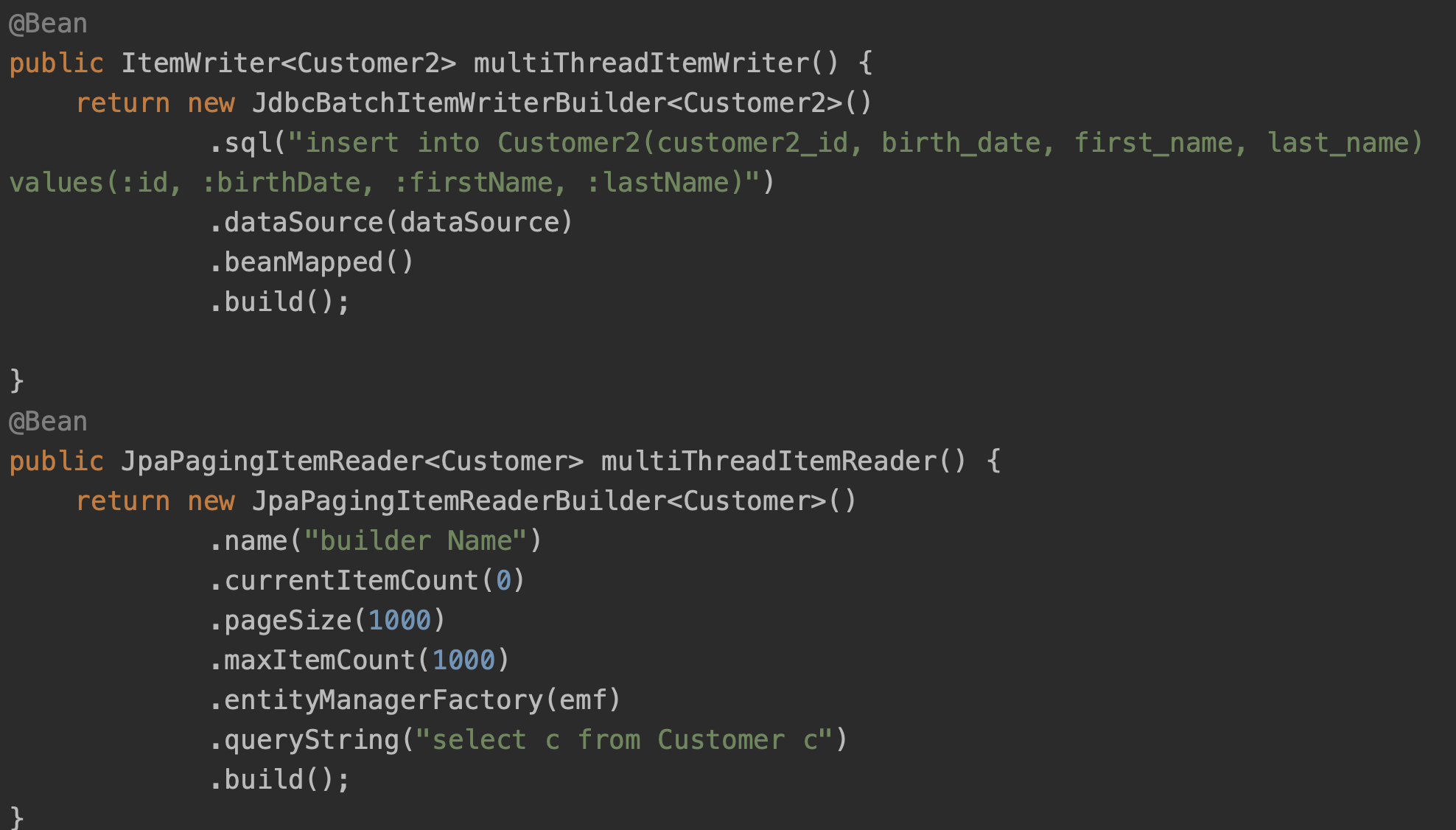
writer는 동기화 여부를 상관하지 않아도 되기 떄문에, 가볍게 생성을 한다.
Reader는 동기화 처리를 신경써야하는데, 해당 부분때문에 JpaPagingItemReaderBuilder를 사용한다.
동기화랑 이거랑 무슨 상관일까
JpaPagingItemReader는 Paging을 구현한 구현체이다.
JpaPagingItemReader는 JdbcPagingItemReader 이 두개는 Paging 기반의 구현체이고,
해당 doread()메소드가 동기화 처리가 되어있기 때문에, read 작업 자체가 thread safe하다.
추가) 멀티쓰레드의 step은 기본적으로 싱글톤 빈을 전략으로 사용하기 때문에StepScope로 프록시 객체를 생성하지 않아도 자동으로 싱글톤관리가 된다.
2. Partioning
멀티쓰레딩과 더불어 partioning은 대표적인 스프링 배치의 스케일링 기술이다.
일반적인 기술을 사용하다가 데이터가 증가하여 더많은 데이터를 사용해야하는 경우에 해당 방법을 고려 해볼 수 있다.
멀티쓰레드 기법이 단일 step에서 각 Chunk별로 여러쓰레드에서 처리를 했다면,
해당 코드의 변경없이 스케일링을 하여, 더 많은 데이터를 처리할 수 있다는 장점이 있다.

멀티쓰레드는 하나의 스탭을 Chunk별로 여러 쓰레드에서 처리를 했다면,
파티셔닝은 Marster Step이 해당 Step을 여러개의 Worker로 분할하여, 처리하게끔 하는 차이가 있다.
멀티쓰레드는
각 쓰레드가 어떤 작업을 처리하는지 세밀하게 조정이 불가하고
ItemReader와 Writer가 멀티쓰레드 환경을 지원하는지 여부가 굉장히 중요했다.
반면 파티셔닝은 독립적인 step을 구성하고 그에따른 각각의 StepExecution 파라미터 환경을 가지게 하여 처리하게 된다.
ItemReader,Writer에 대한 멀티쓰레드 지원여부가 중요하지 않다.
PartionHandler는 master Step이 worker Step을 어떻게 관리 할지를 결정한다.
-어느 Step을 worker step으로 두고 병렬로 실행하게 할지
-병렬로 수행하는 경우 쓰레드 풀은 어떻게 관리를 할지
-gridsize를 몇으로 둘지
-모든 작업이 완료 되었는지
위 사항들외 많지만 해당 사항들을 관리하는걸 결정할 수 있고, 구현체는 크게 두가지가있다.
- TaskExecutorPartitionHandler
- 단일 JVM 내에서 분할 개념을 사용할 수 있도록 같은 JVM 내에서 스레드로 분할 실행
- MessageChannelPartitionHandler
- 원격의 JVM에 메타 데이터를 전송
SimpleAsyncTaskExecutor를 사용할 경우 쓰레드 무한 생성될 수 있기 때문에 쓰레드풀을 이용해서 쓰레드를 지정해주는ThreadPoolTaskExecutor를 사용해주자
partitionHandler
PartitionHandler는 매니저 step이 worker step을 어떻게 다룰지를 정의한다.
1) TaskExecutorPartitionHandler
2) setStep(step1())
Worker로 실행할 Step을 지정한다.
Partioner가 만들어준 StepExecutions 환경에서 개별적으로 실행된다.
3)setTaskExecutor(executor())
멀티쓰레드로 실행하기 위해 TaskExecutor를 지정한다.
4) setGridSize
쓰레드 개수와 gridSize를 맞추기 위해서 poolSize를 gridSize로 등록한다.
이번 예제에서는 poolSize에 5를 등록할 예정입니다.

3)에 등록한 executor()는 아래와 같이 구현한다.

기본 예제로 SimpleAsyncTaskExecutor를 사용할 수도 있겠지만, SimpleAsyncTaskExecutor를 사용할 경우
쓰레드가 계속 생성되어, 장애 발생될 확률이 높다.


마스터 Step은 어떤 Step을 worker로 지정할지 결정한다.
이때 사용할 PartitionHandler를 지정해준다.
2) step1에 사용될 파티셔너를 등록해준다.
3) 파티셔닝될 Step을 등록한다.
총 정리하면, step1Manager에서는 사용할 스탭의 파티션을 적용하고, 파티션 핸들러를 적용한다.
패티션 핸들러에는 쓰레드 풀과,워커로 사용될 스탭을 지정해준다. 또한 할당할 파티션수(grid) 사이즈가 지정된 것을 볼수 있다.

각각의 min,max 값을 받아서 targetSize로 minId,maxid를 파티셔닝해서 ExecutionContext로 리턴한다.
<정리>
하나의 Jvm내에서 멀티 스레드로 처리하는 방법이다.
파티셔닝
partitioner에서 데이터를 나누고 각 스텝에 나눈 데이터를 분배하여, 스텝에서는 분배받은 데이터를 가지고 프로그램을 수행한다.
스레드 측면에서 보면 partitioner라는 스레드가 데이터를 나눠서 각 스텝에 나눠주는데 이스텝은 별도의 스레드에서 동작한다.
즉 ItemReader,ItemWriter가 thread-safe하지 않아도 된다.
Multi thread step의 경우, ItemReader,ItemWriter는 thread-safe해야한다.
Multi thread step의 경우, step의 chunks를 여러 스레드가 번갈아 가면서 처리하는 구조이다.
장단점
partitioner의 장점은 데이터를 분배하고 멀티 스레드로 처리하기에 속도가 잘 나온다.
로그가 뒤섞여 나올수있다
데이터를 분배받는 bean은 멀티 스레드에 안전하도록 개발해야한다.
1개의 스레드가 장애 발생시 다른 스레드에 영향이 미칠수있도록 드문경우, 잘못 설계된 경우 발생한다.
'Develop > [Spring Batch]' 카테고리의 다른 글
| [Spring Batch] Tasklet vs Chunks 차이 (0) | 2022.04.11 |
|---|---|
| [Spring Batch] 스프링 배치 트랜잭션 관리 청크기반으로 하는 이유 (0) | 2022.04.11 |
| [Spring Batch] Chunk란? (0) | 2022.04.10 |
| [Spring Batch] How to FailOver(Retry) (0) | 2022.04.10 |
| [Spring Batch] How to FailOver(Skip) (0) | 2022.04.10 |


